How Kinetic Data implemented structured logging to drastically improve application support.
How Kinetic Data implemented structured logging to drastically improve application support.
What is the new structured logging feature in the Kinetic Data products?
Starting with Kinetic Task v4.3, Kinetic Core v2.0.2, Bridgehub v1.2, and Filehub v1.2 a new feature was implemented in these applications referred to as ‘structured logging’. Structured logging essentially is ensuring that a log file is a preset, consistent, and machine readable format. In our most recent releases we provide the following new structured log files:
structured.access.log
Log entry for every time a resource is accessed through the kinetic application. Who, when, how long, what, etc. This can be used for analytics.
structured.application.log
Contains entries for application warnings, errors, debug, or trace level messages. Used for troubleshooting.
structured.authentication.log
Authentication attempts get logged to this file. Who, when, and authentication type. Used for troubleshooting and auditing.
structured.system.log
Heartbeat checks, application startups and shutdowns, and other non-frequent events like that are the purpose for this log file.
Okay… What is the benefit?
Well, because these logs are machine friendly they can then be digested by Filebeat and thus Elasticsearch. Now the log files can provide more functions than diagnostics or troubleshooting, they can also provide analytics and monitoring as well.
Diagnostics and Troubleshooting
Fast full text searching on error messages
Searching by date and time ranges for errors
Find all users who experienced a specific error
Find any errors a specific user encountered
Check the average response times for a specific user over time. See exactly when things started to get slower for that user.
Check for any errors in any application in one search: Core, Task, Filehub, Bridgehub. All at once.
Monitoring and Alerting
Setup an alert for whenever there are more than 100 failed login attempt in a minute.
Alert on API calls taking longer than one second.
Monitor for anytime webhooks fail to execute.
Monitor current system usage per application.
Analytics, Auditing, and Reporting
Put together a dynamic graph showing the average response times for requests.
Trend on how many errors occur per hour. Little hint, you’ll see a bell curve most likely.
Quickly throw together a pie chart showing the top ten active users.
Find out the last time a specific user tried to login.
How did we use this to our benefit?
Here are a few things that we’ve already used Elasticsearch, Filebeat, and Kibana for with our structured logs:
Discovered numerous HEAD HTTP requests resulting in 405 HTTP responses
When John reported a kinops page showing a 500 error, the log entry for the error was quickly retrieved despite not knowing exactly when the error occurred. We were simply able to query for: app.user:john.sundberg@kineticdata.com AND level:(WARN ERROR)
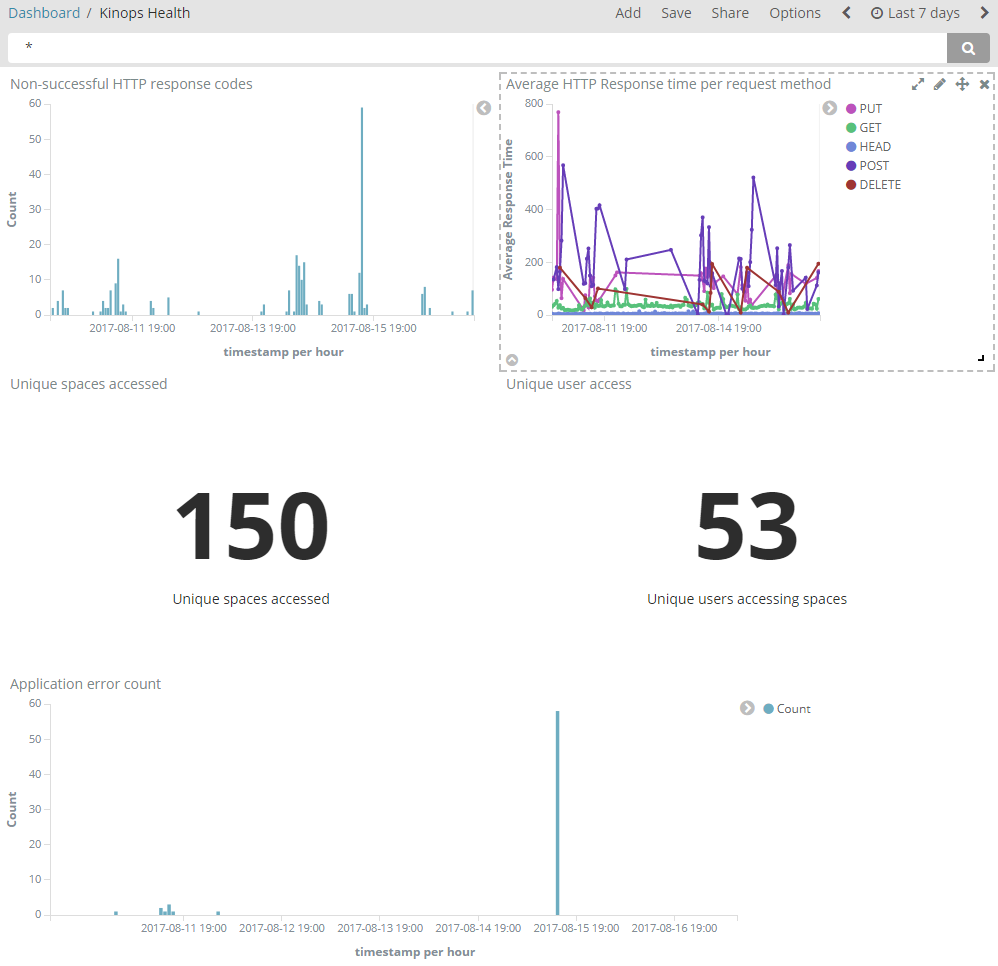
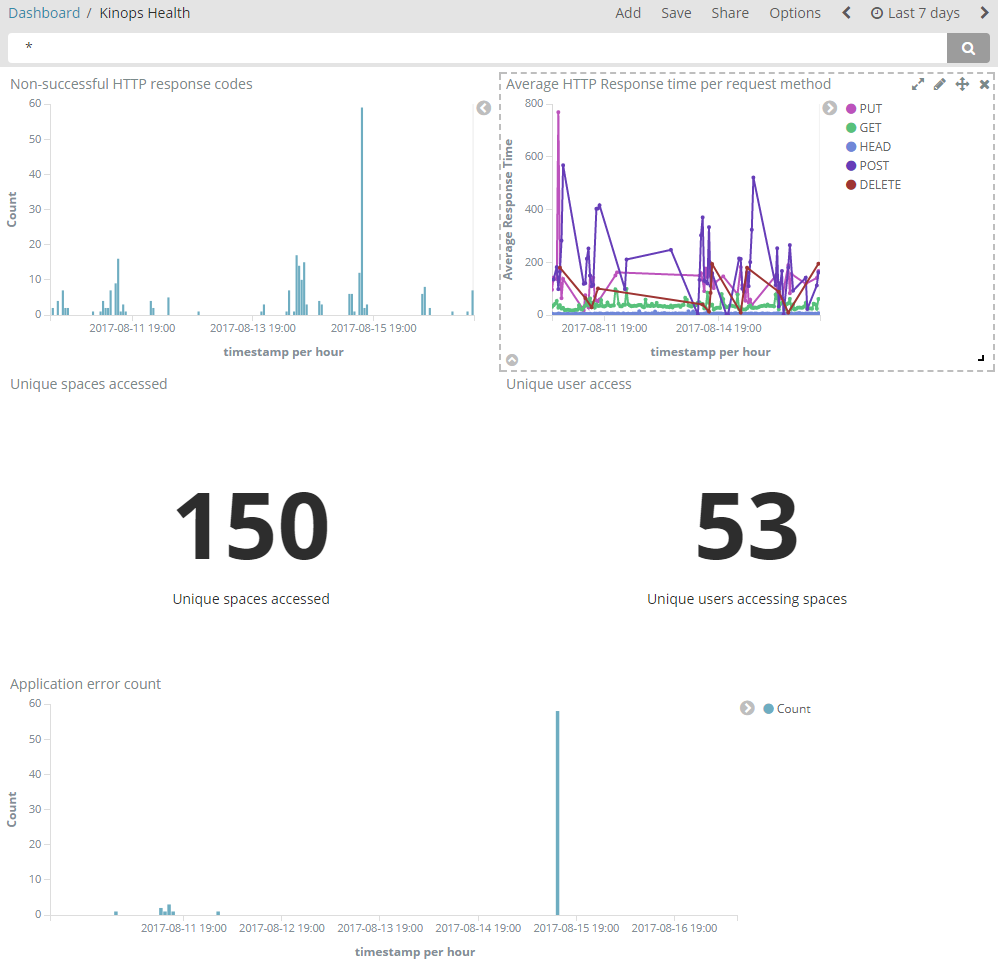
Developed a ‘kinops Health’ Dashboard to show average request response times, errors counts, and access volume by spaces and users.
Setup alerting for when webhooks fail.
Helped improve our structured logging before release by using Filebeat and Elasticsearch.
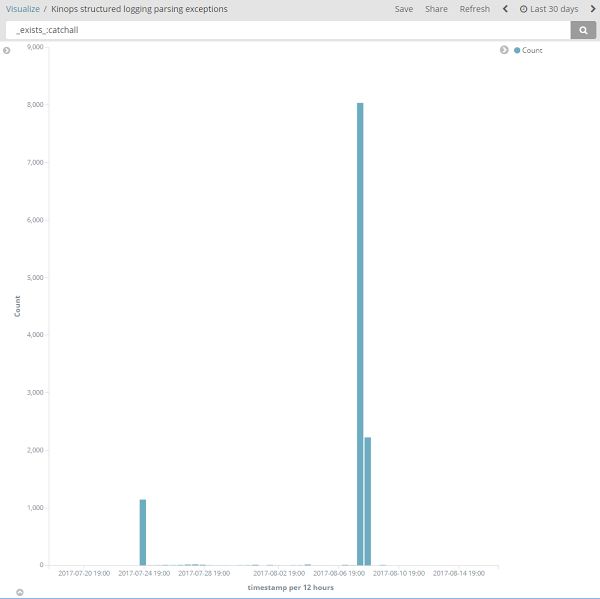
Found multiple log entries that did not match our expected patterns which forced us to clean up our logging in the application.
When running a report to find top active IP addresses on kinops.io, we did not find nearly as many as we were expecting. This led us to realize we forgot to add support for X-Forwarded-For to get user IP addresses anytime a proxy is used.
Words, words, words. Show me something cool.
The following screenshots of graphs are all from Kibana
Image shows HTTP response codes and Request times.
This was a graph put together in less time than it took to listen to Waterfalls by TLC. The purpose of creating it was to illustrate how easy it is to get a feel for a user’s experience overtime.